Introduction
对于大部分应用开发者来说,Java编译器指的是JDK自带的javac指令。这一指令可将Java源程序编译成.class文件,其中包含的代码格式我们称之为Java bytecode(Java字节码)。这种代码格式无法直接运行,但可以被不同平台JVM中的interpreter解释执行。由于interpreter效率低下,JVM中的JIT compiler(即时编译器)会在运行时有选择性地将运行次数较多的方法编译成二进制代码,直接运行在底层硬件上。Oracle的HotSpot VM便附带两个用C++实现的JIT compiler:C1及C2。
与interpreter,GC等JVM的其他子系统相比,JIT compiler并不依赖于诸如直接内存访问的底层语言特性。它可以看成一个输入Java bytecode输出二进制码的黑盒,其实现方式取决于开发者对开发效率,可维护性等的要求。Graal是一个以Java为主要编程语言,面向Java bytecode的编译器。与用C++实现的C1及C2相比,它的模块化更加明显,也更加容易维护。Graal既可以作为动态编译器,在运行时编译热点方法;亦可以作为静态编译器,实现AOT编译。在Java 10中,Graal作为试验性JIT compiler一同发布(JEP 317)。这篇文章将介绍Graal在动态编译上的应用。有关静态编译,可查阅JEP 295或Substrate VM。
Tiered Compilation
在介绍Graal前,我们先了解HotSpot中的tiered compilation。前面提到,HotSpot集成了两个JIT compiler — C1及C2(或称为Client及Server)。两者的区别在于,前者没有应用激进的优化技术,因为这些优化往往伴随着耗时较长的代码分析。因此,C1的编译速度较快,而C2所编译的方法运行速度较快。在Java 7前,用户需根据自己的应用场景选择合适的JIT compiler。举例来说,针对偏好高启动性能的GUI用户端程序则使用C1,针对偏好高峰值性能的服务器端程序则使用C2。
Java 7引入了tiered compilation的概念,综合了C1的高启动性能及C2的高峰值性能。这两个JIT compiler以及interpreter将HotSpot的执行方式划分为五个级别:
- level 0:interpreter解释执行
- level 1:C1编译,无profiling
- level 2:C1编译,仅方法及循环back-edge执行次数的profiling
- level 3:C1编译,除level 2中的profiling外还包括branch(针对分支跳转字节码)及receiver type(针对成员方法调用或类检测,如checkcast,instnaceof,aastore字节码)的profiling
- level 4:C2编译
其中,1级和4级为接受状态 — 除非已编译的方法被invalidated(通常在deoptimization中触发),否则HotSpot不会再发出该方法的编译请求。
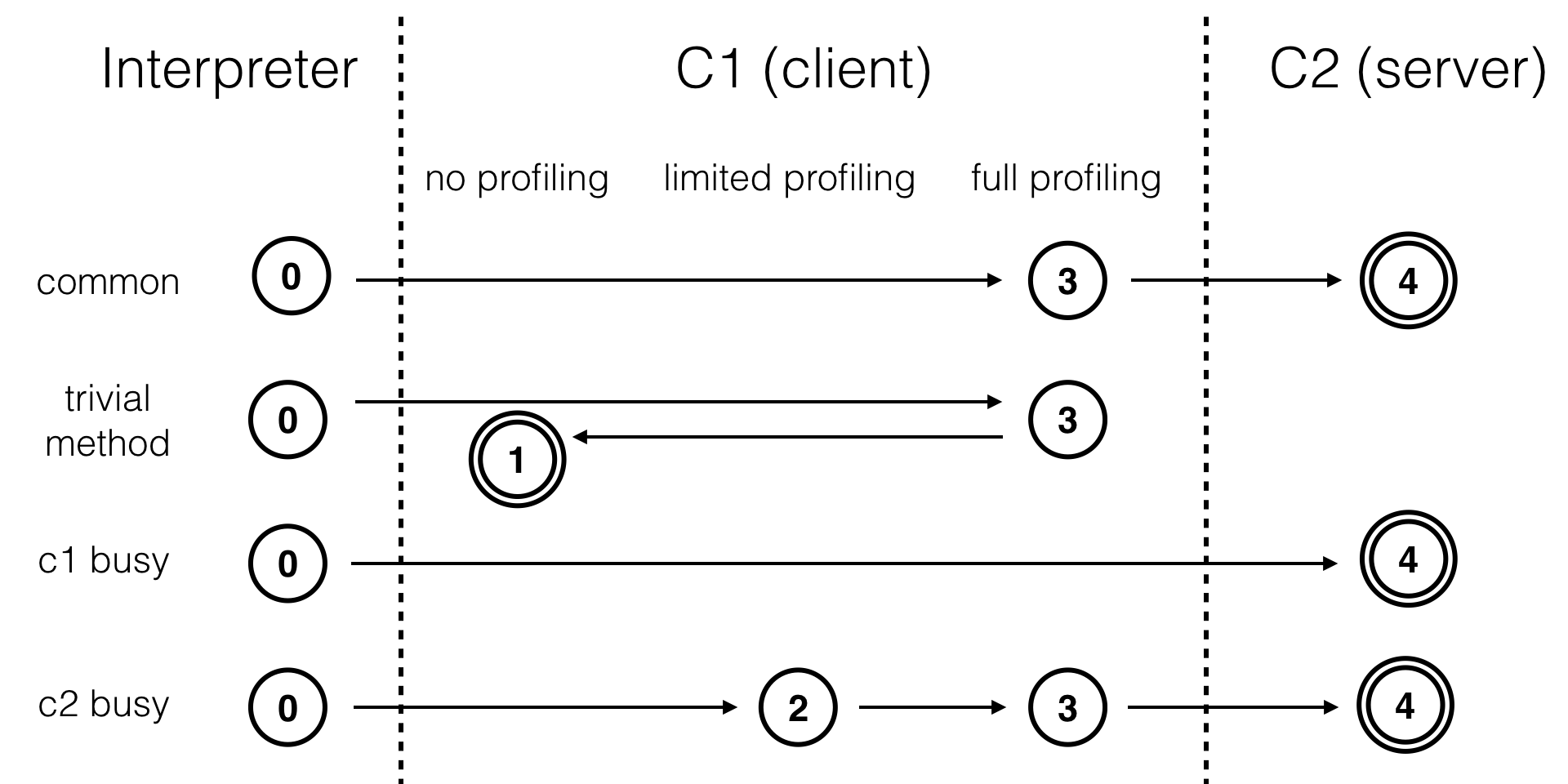
上图列举了4种编译模式(非全部)。通常情况下,一个方法先被解释执行(level 0),然后被C1编译(level 3),再然后被得到profile数据的C2编译(level 4)。如果编译对象非常简单,虚拟机认为通过C1编译或通过C2编译并无区别,便会直接由C1编译且不插入profiling代码(level 1)。在C1忙碌的情况下,interpreter会触发profiling,而后方法会直接被C2编译;在C2忙碌的情况下,方法则会先由C1编译并保持较少的profiling(level 2),以获取较高的执行效率(与3级相比高30%)。
Graal可替换C2成为HotSpot的顶层JIT compiler,即上述level 4。与C2相比,Graal采用更加激进的优化方式,因此当程序达到稳定状态后,其执行效率(峰值性能)将更有优势。
早期的Graal同C1及C2一样,与HotSpot是紧耦合的。这意味着每次编译Graal均需重新编译HotSpot。JEP 243将Graal中依赖于HotSpot的代码分离出来,形成Java-Level JVM Compiler Interface(JVMCI)。该接口主要提供如下三种功能:
- 响应HotSpot的编译请求,并分发给Java-Level JIT compiler
- 允许Java-Level JIT compiler访问HotSpot中与JIT compilation相关的数据结构,包括类,字段,方法及其profiling数据等,并提供这些数据结构在Java层面的抽象
- 提供HotSpot codecache的Java抽象,允许Java-Level JIT compiler部署编译完成的二进制代码
综合利用这三种功能,我们可以将Java-Level编译器(不局限于Graal)集成至HotSpot中,响应HotSpot发出的level 4的编译请求并将编译后的二进制代码部署到HotSpot的codecache中。此外,单独利用上述第三种功能可以绕开HotSpot的编译系统 — Java-Level编译器将作为上层应用的类库直接部署编译后的二进制代码。Graal自身的单元测试便是依赖于直接部署而非等待HotSpot发出编译请求;Truffle亦是通过此机制部署编译后的语言解释器。
Graal v.s. C2
前面提到,JIT Compiler并不依赖于底层语言特性,它仅仅是一种代码形式到另一种代码形式的转换。因此,理论上任意C2中以C++实现的优化均可以在Graal中通过Java实现,反之亦然。事实上,许多C2中实现的优化均被移植到Graal中,如近期由其他开发者贡献的String.compareTo intrinsic的移植。当然,局限于C++的开发/维护难度(个人猜测),许多Graal中被证明有效的优化并没有被成功移植到C2上,这其中就包含Graal的inlining算法及partial escape analysis(PEA)。
Inlining是指在编译时识别callsite的目标方法,将其方法体纳入编译范围并用其返回结果替换原callsite。最简单直观的例子便是Java中常见的getter/setter方法 — inlining可以将一个方法中调用getter/setter的callsite优化成单一内存访问指令。Inlining被业内戏称为优化之母,其原因在于它能引发更多优化。然而在实践中我们往往受制于编译单元大小或编译时间的限制,无法无限制地递归inline。因此,inlining的算法及策略很大程度上决定了编译器的优劣,尤其是在使用Java 8的stream API或使用Scala语言的场景下。这两种场景对应的Java bytecode包含大量的多层单方法调用。
Graal拥有两个inliner实现。社区版的inliner采用的是深度优先的搜索方式,在分析某一方法时,一旦遇到不值得inline的callsite时便回溯至该方法的调用者。Graal允许自定义策略以判断某一callsite值不值得inline。默认情况下,Graal会采取一种相对贪婪的策略,根据callsite的目标方法的大小做出相应的决定。Graal enterprise的inliner则对所有callsite进行加权排序,其加权算法取决于目标方法的大小以及可能引发的优化。当目标方法被inline后,其包含的callsite同样会进入该加权队列中。这两种搜索方式都较为适合拥有多层单方法调用的应用场景。
Escape analysis(逃逸分析,EA)是一类识别对象动态范围的程序分析。编译器中常见的应用有两类:如果对象仅被单一线程访问,则可去除针对该对象的锁操作;如果对象为堆分配且仅被单一方法访问(inlining的重要性再次体现),则可将该对象转化成栈分配。后者通常伴随着scalar replacement,即将对对象字段的访问替换成对虚拟局部操作数的访问,从而进一步将对象由栈分配转换成虚拟分配。这不仅节省了原本用于存放对象header的内存空间,而且可以在register allocator的帮助下将(部分)对象字段存放在寄存器中,在节省内存的同时提高执行效率(内存访问转换成寄存器访问)。
1 | public class Foo { |
Java中常见的for-each loop是EA的一大目标客户。我们知道for-each loop会调用被遍历对象的iterator方法,返回一个实现interface Iterator的对象,并利用其hasNext及next接口进行遍历。Java collections中的容器类(如ArrayList)通常会构造一个新的Iterator实例,其生命周期局限于该for-each loop中。如若Iterator实例的构造函数以及hasNext,next方法调用(连同它们方法体中以this为receiver的方法调用,如checkForComodification())都被inline,EA会认为该实例没有逃逸,并采取栈分配及scalar replacement。
1 | public class ArrayList<E> ... { |
理想情况下,Foo.bar会被优化成如下代码:
1 | public class Foo { |
HotSpot的C2便已应用控制流无关的EA实现scalar replacement。而Graal的PEA则在此基础上引入了控制流信息,将所有的堆分配操作虚拟化,并仅在对象确定逃逸的分支materialize。与C2的EA相比,PEA分析效率较低,但能够在对象没有逃逸的分支上实现scalar replacement。如下例所示,如果then-branch的执行概率为1%,那么被PEA优化后的代码在99%的情况下并不会执行堆分配,而C2的EA则100%会执行堆分配。另一个典型的例子是渲染引擎Sunflow — 在运行DaCapo benchmark suite所附带的默认workload时,Graal的PEA判定约27%的堆分配(共占700M)可被虚拟化。该数字远超C2的EA。
1 | // run with -XX:+PrintGC |
Using Graal
在Java 10 (Linux/x64, macOS/x64)中,默认情况下HotSpot仍使用C2,但通过向java命令添加-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler参数便可将C2替换成Graal。
1 | $ java -version |
Oracle Labs GraalVM是由Oracle Labs直接发布的JDK版本。它基于Java 8,并且囊括了Graal enterprise。如果对源代码感兴趣,可直接签出Graal社区版的GitHub repo。源代码的编译需借助mx工具及labsjdk(注:请下载页面最下方的labsjdk,直接使用GraalVM可能会导致编译问题)。
1 | # clone mx |
在graal/compiler目录下使用mx eclipseinit,mx intellijinit或mx netbeansinit可分别生成Eclipse,IntelliJ或NetBeans的工程配置文件。
Useful Links
- Graal publications
- Graal tutorial, slides
- Chris Seaton: Understanding How Graal Works - a Java JIT Compiler Written in Java
Upcoming: advanced topics in Graal compiler
- Debugging compiled code
- Deoptimization & Java-level assumption — SpeculationLog
- Graal method substitution & Snippet
- Implementing JVM intrinsics